

In this post we will discuss about what classification is, and how do we go about classifying in machine learning.
What is Classification?
In machine learning and statistics, classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known.
Wikipedia
So basically, the above definition can be simplified as – ‘To identify which category/class the new set of data belongs to, on the basis of set of data which is already classified.’
Classification is categorised under ‘Supervised Machine Learning‘ for the fact that we have a set of data that is already classified and the model (algorithm) is learning from it to classify new data.
The Output variable is also called as target / class / label.
An instance of classification – an email of text can be classified as belonging to one of two classes: “spam“ and “not spam“. So, ideally we would have a dataset in which emails are already classified as “spam“ and “not spam“ and our job is to predict if any new email is a spam or not.
Similarly, Classification is used in Bank loan defaulter prediction, Identifying Cancer tumor cells, Text Sentiment analysis, handwritten digit recognition, Pedestrian detection.
How do we Classify?
There are several Classification Algorithms in Machine Learning which include the below ones.
- Logistic Regression
- Naive Bayes classifier
- Support vector machines
- k-nearest neighbour
- Decision trees
We will go through each of these in coming articles in depth with math explained wherever possible and example in python.
Logistic Regression
Logistic Regression is a very famous Binary Classification Algorithm. Since it classifies data into 2 categories (‘Spam’ / ‘Not Spam’ , ‘Authentic Transaction’/ ‘Fraudulent Transaction’ etc..) .
Logistic regression uses Logit (sigmoid) function to predict the probability of the data falling into one of the categories, Since we predict probabilities, we always have values 0 to 1.

Logistic Regression uses log(odds) to predict the probability (p) of data falling into a particular class (Let’s say A).
odds = p/(1-p) -> ln(odds) = c + m1x1 + m2x2 + … + mnxn
Naive Bayes Classifier
Naive Bayes classifier is based on Bayes’ theorem with the assumption of independence between every pair of features in the dataset.
Lets say y = class, x1 …xn = predictor variables

P(y) = class probability and P(xi | y) = conditional probability
Support Vector Machines
In Support vector machine, we try to draw a line that separates the categories in training dataset. New data points are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
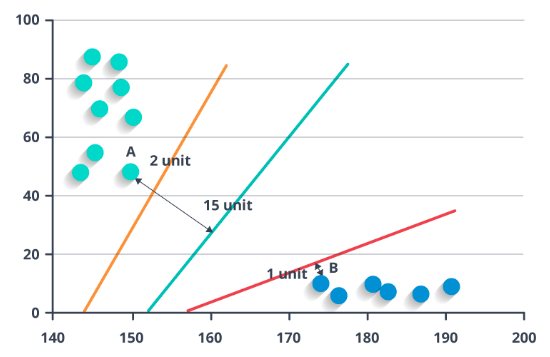
The Green line separates the two categories, and orange, red lines are the Support Vectors which are drawn closest to the edge points of the categories.
k-Nearest Neighbour (KNN)
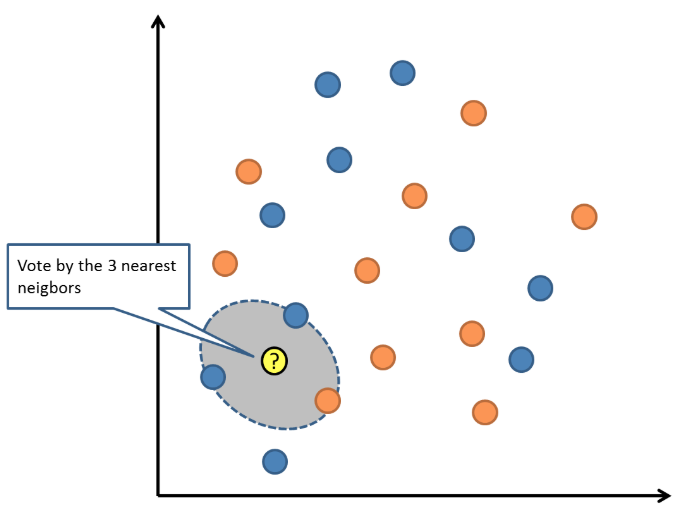
KNN is a type of lazy learning as it does not attempt to construct any model, but simply stores the training data. Classification is computed from a simple majority vote of the k nearest neighbours of each point.
For example, if k=3 and a new data point has to be classified, it checks the closest 3 neighbours and returns the most common class as the prediction.
Decision Trees
Decision tree builds classification model in the form of a tree structure. It produces a sequence of rules from the training data that can be used to classify new data.
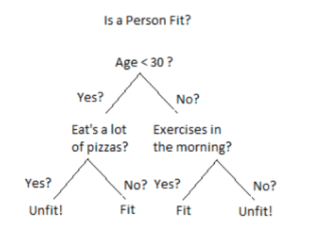
The biggest advantage of Decision Trees is interpretability. Also, nonlinear relationship between the parameters doesn’t affect the tree performance.
I have taken each of the Classification Algorithms and explored them in depth including the math portion and examples in python.
- Logistic Regression
- Naive Bayes Classifier
- Support vector machines
- k-nearest neighbour
- Decision trees

2 thoughts on “Machine Learning – Classification”